Behavioral Cloning¶
model.py¶
In [ ]:
# %load ../../Projects/Project_03/model.py
import csv
import math
import os
import pickle
import time
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import tensorflow as tf
from keras.models import Model
from keras.layers import Dense, Dropout, Flatten, Input, Lambda
from keras.layers.convolutional import Conv2D, Cropping2D
from keras.layers.pooling import MaxPooling2D
from keras.utils import plot_model
# COMMAND LINE FLAGS
flags = tf.app.flags
FLAGS = flags.FLAGS
flags.DEFINE_string('drives', '', 'a ":" separated string of paths to the drive directories')
flags.DEFINE_float('validation_split', 0.2, 'fraction of the training data to be used as validation data')
flags.DEFINE_integer('batch_size', 256, 'batch size')
flags.DEFINE_integer('epochs', 10, 'number of epochs')
flags.DEFINE_integer('convolve', 1, 'length of a moving average filter that is applied to the steering data')
flags.DEFINE_float('correction', 0.0, 'correction for the left and right camera positions')
flags.DEFINE_bool('use_generator', False, 'use a generator to feed data to the model')
flags.DEFINE_float('test_size', 0.33, 'fraction of the data to be used for validation')
flags.DEFINE_integer('random_state', 0, 'random state used by ``train_test_split`` for splitting the data into training and validation sets')
def filename_to_seconds(filename):
"""Convert the timestamp in a filename to seconds
Parameters
----------
filename : str
path to an image file (e.g., '<stuff>/data/drive2/IMG/center_2017_09_09_19_29_38_743.jpg')
Returns
-------
int
``60 * minutes + seconds`` (from the file's timestamp)
"""
minutes = int(filename[-13:-11])
seconds = int(filename[-10:-8])
return 60 * minutes + seconds
def load_drives_list(drives_list, convolve):
"""Load data from all of the drives and return it as a single list
Parameters
----------
drives_list : list
a list of paths to the drive directories
convolve : int
length of a moving average filter that is applied to the steering data
Returns
-------
lines : list
a list with entries [center_img_path, left_img_path, right_img_path, center_measurement]
shape : tuple
the shape of the images
"""
lines = []
for drive in drives_list:
csv_file = os.path.join(drive, 'driving_log.csv')
with open(csv_file, 'r') as f:
reader = csv.reader(f)
temp_lines = [line for line in reader]
image_dir = os.path.join(os.path.abspath(os.path.dirname(csv_file)), 'IMG')
# get the path separator
img_index = temp_lines[0][0].rfind('IMG')
sep = temp_lines[0][0][img_index + 3]
# separate the drive into its constituent recordings
seconds = [filename_to_seconds(line[0]) for line in temp_lines]
recording_starts = [i for i, sec in enumerate(seconds) if i == 0 or sec - seconds[i-1] > 1]
recording_starts = recording_starts + [len(temp_lines)]
recordings = [temp_lines[recording_starts[i]:recording_starts[i+1]] for i in range(len(recording_starts) - 1)]
# the number of recordings
r = len(recording_starts)-1
# the number of raw measurements
m0 = len(temp_lines)
# for tracking the number of pre-processed measurements (i.e., after taking the moving average)
m1 = 0
# load the images and steering measurements
for recording in recordings:
n = len(recording)
# load the measurements and take a moving average
measurements = [float(line[3]) for line in recording]
if convolve != 1:
measurements = list(np.convolve(measurements, np.ones(convolve)/float(convolve), mode='valid'))
# the number of measurements cut off at the start and end due to convolving
border = int((convolve - 1) / 2)
new_lines = [[os.path.join(image_dir, line[0].split(sep)[-1]),
os.path.join(image_dir, line[1].split(sep)[-1]),
os.path.join(image_dir, line[2].split(sep)[-1]),
measurement] for line, measurement in zip(recording[border:n-border], measurements)]
# append the new lines
lines.extend(new_lines)
m1 += len(measurements)
print("Drive '{0}'".format(os.path.split(drive)[-1]))
print("* {0} recording{1}".format(r, 's' if r != 1 else ''))
print("* {0} raw measurements".format(m0))
print("* {0} pre-processed measurements".format(m1))
print("* {0} post-processed measurements\n".format(6*m1))
# get the shape of the images
img0 = cv2.imread(lines[0][0])
shape = img0.shape
print("\n{0} training images of size {1} x {2} x {3}\n".format(6*len(lines), shape[0], shape[1], shape[2]))
return lines, shape
def data_arrays(lines, correction):
"""Load all of the images and steering measurements in ``lines`` and return them as numpy arrays
Parameters
----------
lines : list
a list with entries [center_img_path, left_img_path, right_img_path, center_measurement]
correction : float
correction for the left and right camera positions
Returns
-------
X_train : numpy.ndarray
training images
y_train : numpy.ndarray
training steering angles
"""
images = []
measurements = []
for line in lines:
# get the images and steering measurements
new_images = [cv2.imread(img) for img in line[:3]]
new_measurements = [line[3], line[3] + correction, line[3] - correction]
# add the images and steering measurements
images.extend(new_images)
measurements.extend(new_measurements)
# flip the images and steering angles and add them
images.extend([cv2.flip(img, 1) for img in new_images])
measurements.extend([-x for x in new_measurements])
X_train = np.array(images)
y_train = np.array(measurements)
return X_train, y_train
def data_generator(lines, correction, batch_size):
"""Load images and steering measurements in ``lines`` and yield them as arrays
Parameters
----------
lines : list
a list with entries [center_img_path, left_img_path, right_img_path, center_measurement]
correction : float
correction for the left and right camera positions
batch_size : int
the number of lines to process in each batch
Yields
------
list
``[X_train, y_train] = [images, measurements]`` (shuffled)
"""
num_lines = len(lines)
while True:
shuffle(lines)
for offset in range(0, num_lines, batch_size):
batch_lines = lines[offset:offset+batch_size]
images = []
measurements = []
for line in batch_lines:
# get the images and steering measurements
new_images = [cv2.imread(img) for img in line[:3]]
new_measurements = [line[3], line[3] + correction, line[3] - correction]
# add the images and steering measurements
images.extend(new_images)
measurements.extend(new_measurements)
# flip the images and steering angles and add them
images.extend([cv2.flip(img, 1) for img in new_images])
measurements.extend([-x for x in new_measurements])
X_train = np.array(images)
y_train = np.array(measurements)
print
yield shuffle(X_train, y_train)
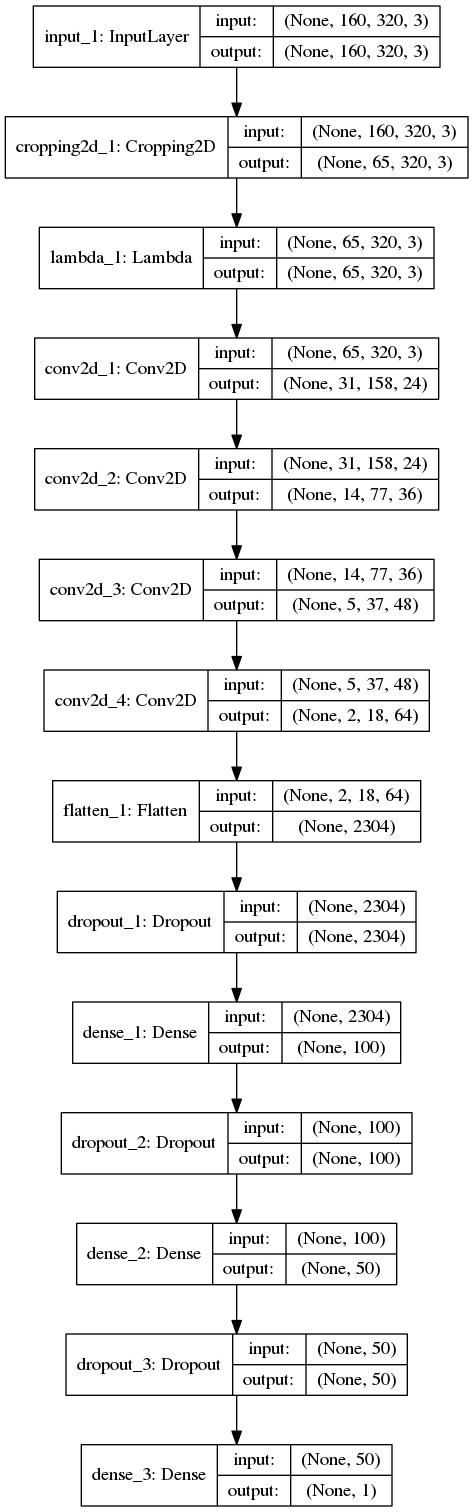
def create_model(shape):
"""Create the Keras model
Parameters
----------
shape : tuple
the shape of the images (aka, the input shape for the first layer)
Returns
-------
model : keras.models.Model
the compiled model
"""
# define the model
inp = Input(shape=shape)
# crop the input
x = Cropping2D(((70, 25), (0, 0)))(inp)
# normalize the input
x = Lambda(lambda x: x / 255. - 0.5)(x)
# add model layers
x = Conv2D(24, (5, 5), strides=(2,2), activation='relu')(x)
x = Conv2D(36, (5, 5), strides=(2,2), activation='relu')(x)
x = Conv2D(48, (5, 5), strides=(2,2), activation='relu')(x)
x = Conv2D(64, (3, 3), strides=(2,2), activation='relu')(x)
x = Flatten()(x)
x = Dropout(0.5)(x)
x = Dense(100)(x)
x = Dropout(0.5)(x)
x = Dense(50)(x)
x = Dropout(0.5)(x)
x = Dense(1)(x)
model = Model(inp, x)
model.compile(optimizer='adam', loss='mse')
return model
def main(drives=FLAGS.drives, validation_split=FLAGS.validation_split, batch_size=FLAGS.batch_size, epochs=FLAGS.epochs, convolve=FLAGS.convolve, correction=FLAGS.correction, use_generator=FLAGS.use_generator,
test_size=FLAGS.test_size, random_state=FLAGS.random_state):
"""This is the function that will be called if this file is run as a script
Parameters
----------
drives : str
a ":" separated string of paths to the drive directories
validation_split : float
fraction of the training data to be used as validation data
batch_size : int
batch size
epochs : int
number of epochs
convolve : int
length of a moving average filter that is applied to the steering data
correction : float
correction for the left and right camera positions
use_generator : bool
if True, a generator will be used to feed data to the model; otherwise, the data will be loaded as numpy arrays
test_size : float
fraction of the data to be used for validation
random_state : int
random state used by ``train_test_split`` for splitting the data into training and validation sets)
"""
assert convolve % 2 == 1, '`convolve` must be odd.'
# parse `drives`
drives_list = drives.split(':')
# load the data
t0 = time.time()
lines, shape = load_drives_list(drives_list, convolve)
if not use_generator:
X_train, y_train = data_arrays(lines, correction)
else:
batch_size = int(batch_size / 6)
train_samples, validation_samples = train_test_split(lines, test_size=validation_split)
train_generator = data_generator(train_samples, correction, batch_size)
validation_generator = data_generator(validation_samples, correction, batch_size)
print('Time to load data = {0:.3f} seconds\n\n'.format(time.time() - t0))
# create the model
model = create_model(shape)
# save a visualization of the model
plot_model(model, show_shapes=True, to_file='../../Projects/Project_03/model.png')
# train the model
t0 = time.time()
if not use_generator:
history_object = model.fit(X_train, y_train, batch_size=FLAGS.batch_size, epochs=FLAGS.epochs, validation_split=validation_split, shuffle=True)
else:
steps_per_epoch = int(math.ceil(len(train_samples)/batch_size))
validation_steps = int(math.ceil(len(validation_samples)/batch_size))
history_object = model.fit_generator(train_generator, epochs=FLAGS.epochs, steps_per_epoch=steps_per_epoch, validation_data=validation_generator, validation_steps=validation_steps)
print('\n\nTime to train the model = {0:.3f} seconds'.format(time.time() - t0))
# save the model
model_h5 = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(drives_list[0]))), 'model.h5')
print('\nSaving model as \'{0}\''.format(os.path.basename(model_h5)))
model.save(model_h5)
# save the model training history
history_output = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(drives_list[0]))), 'history.pickle')
print('\nSaving history object as \'{0}\''.format(os.path.basename(history_output)))
with open(history_output, 'wb') as f:
pickle.dump(history_object.history, f)
if __name__ == '__main__':
main()
Run the script from the command line¶
In [1]:
%%bash
export KERAS_BACKEND=tensorflow
export datadir=../../Projects/Project_03/data
export drives=$datadir/drive0:$datadir/drive1:$datadir/drive2:$datadir/drive3
export drives=$drives:$datadir/recover_right1:$datadir/recover_right2:$datadir/recover_right3
export drives=$drives:$datadir/recover_left1:$datadir/recover_left2
export drives=$drives:$datadir/bobbie2
python ../../Projects/Project_03/model.py --drives $drives --convolve 11 --correction 0.2 --epochs 20
Model Architecture¶